A Look at the State of The Art in Japanese-English Neural Machine Translation
Project Overview
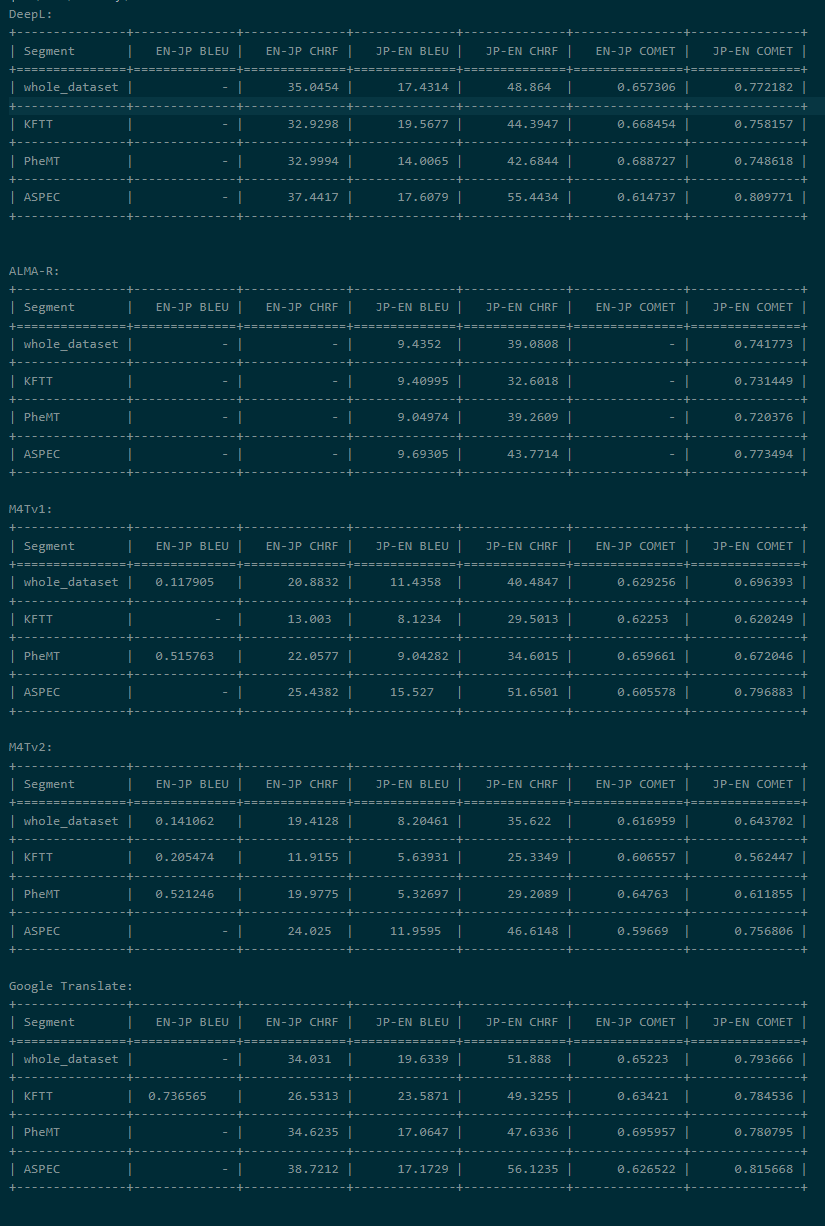
One Liner: This study looks into how the state of the art machine translation models perform on not massively-crawled datasets for a medium-resource language pair: Japanese and English.
Machine translation has seen significant advancements in recent years, largely due to the availability of large-scale parallel corpora. However, the quantity and quality of crawled parallel data for machine translation, particularly for low-to-medium-resource language pairs such as Japanese and English, is lacking in comparison to very high-resource language pairs that are more similar such as English to other European languages. This study investigates the shortcomings of current state of the art Neural Machine Translation models by assembling a dataset comprised of types of data likely to be less common in massive automatically gathered datasets such as more colloquial language - which can be found in user generated content - or more technical language - which can be found in research papers.
Video available at this link.
Screenshots
4 image(s)