Synthetic Audio Detector (SAD)
Project Overview
One Liner: Sometimes the best way to deal with AI... is AI.
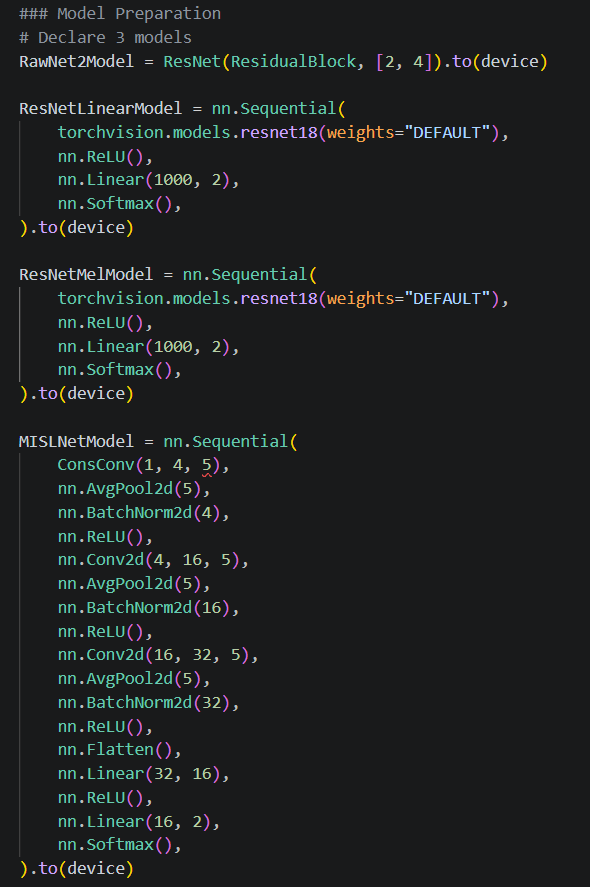
The Synthetic Audio Detector (SAD) is designed as an easy-to-use utility to distinguish between synthetic and authentic human speech. The proposed system employs an ensemble of specialized expert models, consisting of two ResNet-based architectures and one MISL-Net-style model. Specifically, the ensemble includes a RawNet-style model that operates directly on the raw audio waveform, as well as two ResNet models that process a mel-spectrogram and linear spectrogram representations respectively. By leveraging complementary feature representations across these expert models, the SAD functions as a robust voice authentication mechanism and provides a foundation for future development into a long-term voice phishing detection system. The final iteration exhibited an AU-ROC of 0.9688, and an Equal Error Rate (EER) of 0.0751.
No video available.
Screenshots
2 image(s)